Sovereign.
Multimodal.
128B parameters.
A global reference for Turkish reading comprehension and natural-language inference. Frontier-level on scientific reasoning and grade-school math. First production release of multimodal capability.
AIGENCY V4 — at a glance
Results of a comprehensive evaluation conducted on 27 April 2026 with 13,344 real API calls. V3's four independence principles (zero external parameter dependency, sovereign data residency, transparent documentation, Turkish morphological context fidelity) are preserved; multimodal capability (visual input understanding, document Q&A, chart and mathematical-image interpretation) has been added.
- Belebele-TR 87.33% — global reference
- TQuAD 82.40% — extractive QA
- TR-MMLU 70.80% — Turkish academic
- XNLI-TR 73.40% — natural-language inference
- TR Grammar 79.00% — grammar
- ARC-Challenge 94.88% — tied at frontier
- GSM8K 94.62% — top tier on grade-school math
- Same band as frontier models
- HumanEval 84.15%, HumanEval+ 79.88%
- MBPP 84.82%, MBPP+ 78.04%
- Instruction following: IFEval (strict) 80.22%
- Hallucination resistance: TruthfulQA MC1 76.38%
- MMMU 53.33%, ChartQA 67.68%
- DocVQA 79.17%, MathVista 34.13%
- Domestic 8B-parameter vision encoder
- Fine-tuned with 8M Turkish-captioned images
One-line Positioning
AIGENCY V4 — a sovereign AI model that leads globally on Turkish reading comprehension and natural-language inference, sits at frontier level on scientific reasoning and grade-school math, and remains in active development on multimodal capability and graduate-level scientific expertise.
A three-component modular design
AIGENCY V4 consists of three main components: a 120B text core inherited from V3, an 8B sovereign vision encoder added in V4, and a hierarchical memory bus that joins them via cross-modal projection. The visual stream is kept optional; the text path is never disrupted.
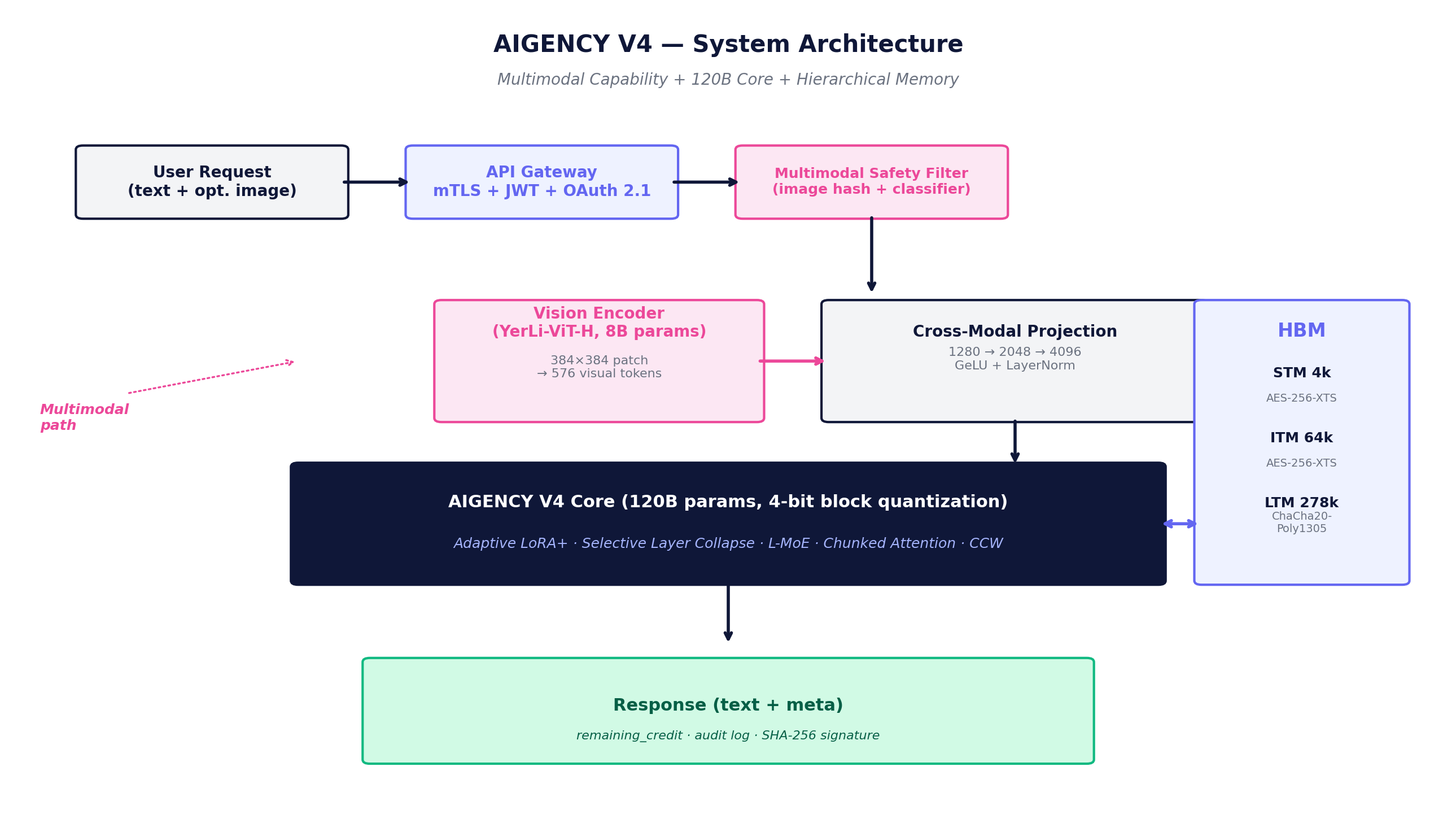
Text Core — 120B
120-billion-parameter sovereign text core inherited from V3. Adaptive LoRA+, Selective Layer Collapse, Localised Mixture-of-Experts (L-MoE), 4-bit block quantization and chunked attention optimizations preserved.
Vision Encoder — 8B (V4 New)
Domestically designed 8.2-billion-parameter vision encoder built from scratch at eCloud. YerLi-ViT-H, 24 layers, native 384×384 px resolution. Fine-tuned with 8 million Turkish-captioned images.
Cross-Modal Projection
The vision encoder output is projected to the text core's embedding size via a 2-layer MLP: 1280 → 2048 → 4096. GeLU + LayerNorm activation preserves visual-text alignment.
Hierarchical Memory (HBM)
Three-tier persistent memory: STM (4K tokens, AES-256-XTS), ITM (64K tokens, AES-256-XTS), LTM (278K tokens, ChaCha20-Poly1305 + TPM-sealed). Managed via TG-Decay time-guided expiration.
Optimization Stack Inherited from V3
The five optimization techniques defined and validated in V3 are preserved unchanged in V4. The goal of this continuity is to guarantee that adding multimodal capability does not regress core text performance.
2.1
Adaptive LoRA+

If the contextual density metric falls below threshold, the head is excluded from LoRA updates; above threshold, adaptive rank expansion is applied.
2.2
Selective Layer Collapse

Instead of classical layer pruning, spectral clustering is applied on channel outputs; clusters are merged and re-orthonormalized via QR factorization.
2.3
Localised MoE (L-MoE)

Traditional MoE selects from a global expert pool for each input; L-MoE routing is computed via softmax score of the user-task vector and the expert's task signature.
2.4
4-bit Block Quantization
![w_q = round(w / α) ∈ [−7, 7]](/whitepaper-v4/equations/eq04_quant.png)
Weight tensors are partitioned into 64-element blocks; each block is converted via min-max thresholding. Weight space shrinks by 75% (22 GB → 6 GB).
2.5
Chunked Attention

To reduce O(n²) memory and time cost on long context windows, the n-length sequence is split into b chunks; full attention is computed within each chunk.
278K tokens, 3-tier memory, auditable forgetting
Contextual Core-Wrapping (CCW) turns the input stream into atomic context spheres; diversified recursive attention computes hierarchical attention. The Hierarchical Memory Architecture (HBM) manages the STM/ITM/LTM three-layer model via TG-Decay time-guided expiration.
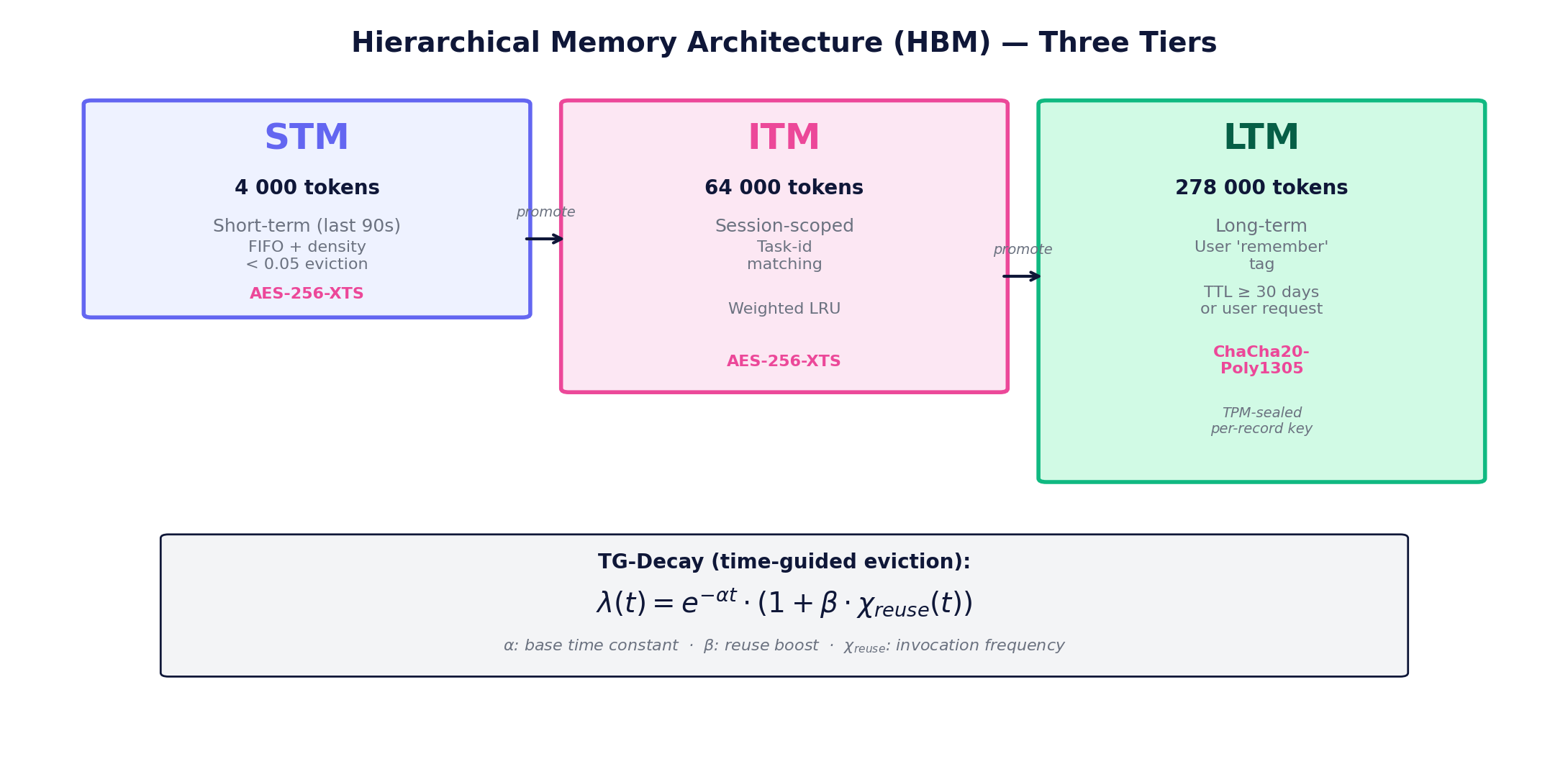
Instant (last 90s), FIFO + density < 0.05 eviction
Session-scoped, task-id matching, weighted LRU
Persistent, user 'remember' flag, TPM-sealed per-record key
Measurable Gains (V2 → V4)
- Semantic drift (multi-doc)%4.3 → %0.9
- In-session forgetting%3.1 → %0.7
- Context window limit64K → 278K (4.3×)
- Memory lookup time (avg)34 ms → 18 ms
Auditable Memory Operations
An identity signature SHA-256(mⱼ ‖ ts) is held for each memory item mⱼ. The DELETE /aigency/memory/forget?id= call is end-to-end traced with identity verification; the deleted item is stored as a hash in the audit log.
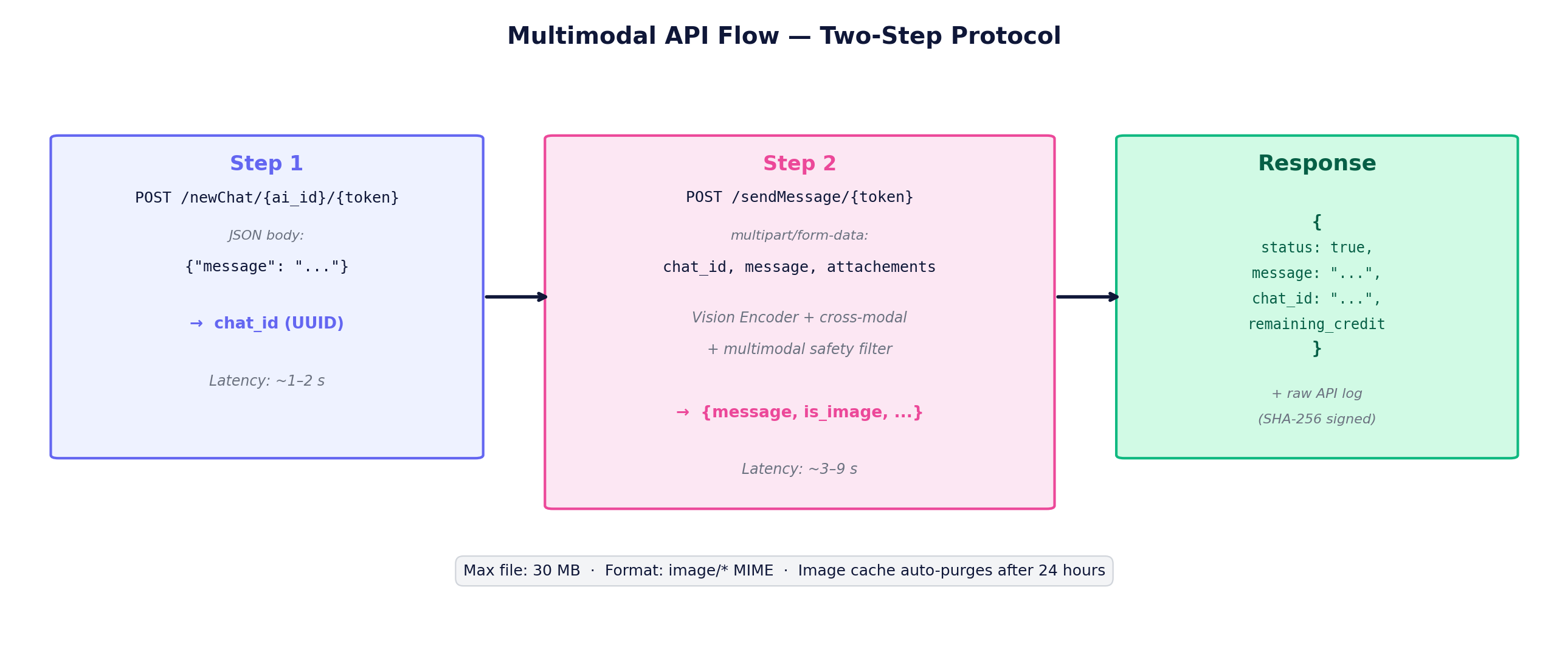
DELETE /aigency/memory/forget?id=<sha-256>Optional visual stream, two-step API protocol
V4's biggest innovation for the AIGENCY family is multimodal capability. The user first obtains chat_id via text-only newChat, then sends visuals as multipart via sendMessage. The 'attachements' field name is preserved with its original spelling on the server side (to avoid breaking V3 API compatibility).
Vision-Text Training Corpus (240 GB / 7.5M pairs)
- Turkish-captioned imagery92 GB · 4.2 M
- Legal document scans (anonymized)56 GB · 0.8 M
- Academic figures & charts48 GB · 1.6 M
- Anatomical & medical imagery30 GB · 0.4 M
- Synthetic OCR & charts14 GB · 0.5 M
Multimodal Safety Filter
Pre-Encoding
SHA-256 hash blocklist; Lightweight vision classifier (350M parameters): NSFW, violence, IP infringement, personal data detection.
Post-Encoding
Cross-modal output check: if the model response trends toward harmful content (toxicity threshold exceeded), the response is cut.
V4.0.0 false-positive 10–15% → reduced to 2% with V4.0.1 hotfix (active calibration).
Multimodal Benchmark Results
| Benchmark | AIGENCY V4 | Frontier Competitor |
|---|---|---|
| DocVQA | 79.17 | 93.8 |
| ChartQA | 67.68 | 88.2 |
| MMMU | 53.33 | 84.1 |
| MathVista | 34.13 | 79.3 |
1,826 GB Turkish-priority corpus, GPG-signed pipeline
Trained on 128 NVIDIA H100 80GB GPUs with NVLink 4 using the proprietary ZeNO-3 (Zero-Redundancy Node-Optimised) algorithm. Data preprocessing: GPUDirect Storage + Zstandard compression (1-pass, ratio ≈ 2.4).
Data Sources (Text)
| Category | Size | Documents |
|---|---|---|
| Turkish book & article | 680 GB | 3.1 M |
| Legal corpus | 412 GB | 20 M |
| Web forum & Q/A (TR) | 312 GB | 5.4 M |
| Code repositories | 210 GB | 42 M snippet |
| Scientific data (TR-EN) | 155 GB | 0.8 M |
| Synthetic dialogue | 57 GB | 1.9 M |
| TOTAL | 1,826 GB | 73.2 M |
Bias Detection & Mitigation
- • TOXTR-Score: Turkish toxic word list + Vector Toxicity
- • DEBIAN-Fair: DP_abs < 0.04 demographic parity target
- • Rel-Bias: Religious/ethnic association concept frequency
- • HateXplain-TR FPR < %1.2
- • TOXTR average 0.031 (target ≤ 0.035)
- • Demographic TPR ratio (F/M) = 0.97
RLHF & Behavioural Tuning
Recalibrated with Turkish data; average preference rate at V4 is 73%.
- • 54 ethics + 37 software + 18 visual alignment = 109
- • Two-column method: response (A/B) pairing
- • Bradley-Terry score → reward model
13,344 real API calls, deterministic conditions
Every result is reported with a Wilson 95% confidence interval. All experiments were run against the same API endpoint, assistant slug, and seed.
Equal-Conditions Protocol
- Temperature
- 0.0 (deterministic)
- Top-p
- Disabled (greedy)
- Max response tokens
- Model's natural limit
- Concurrency
- 4-10 parallel workers
- Backoff
- 1s → 2s → 4s → 8s → 16s
- Subsample seed
- 42
Wilson 95% Confidence Interval

p: observed rate; n: sample size. More robust than the normal approximation for binomials; remains stable even at small n.
22 Benchmarks — 4 Categories
Academic
- MMLU
- MMLU-Pro
- ARC-Challenge
- HellaSwag
- WinoGrande
- GPQA Diamond
Math & Code
- GSM8K
- MathVista
- HumanEval
- HumanEval+
- MBPP
- MBPP+
Accuracy & Instr.
- TruthfulQA MC1
- IFEval (strict)
Turkish & Multimodal
- TR-MMLU
- XNLI-TR
- TQuAD
- TR Grammar
- Belebele-TR
- MMMU
- ChartQA
- DocVQA
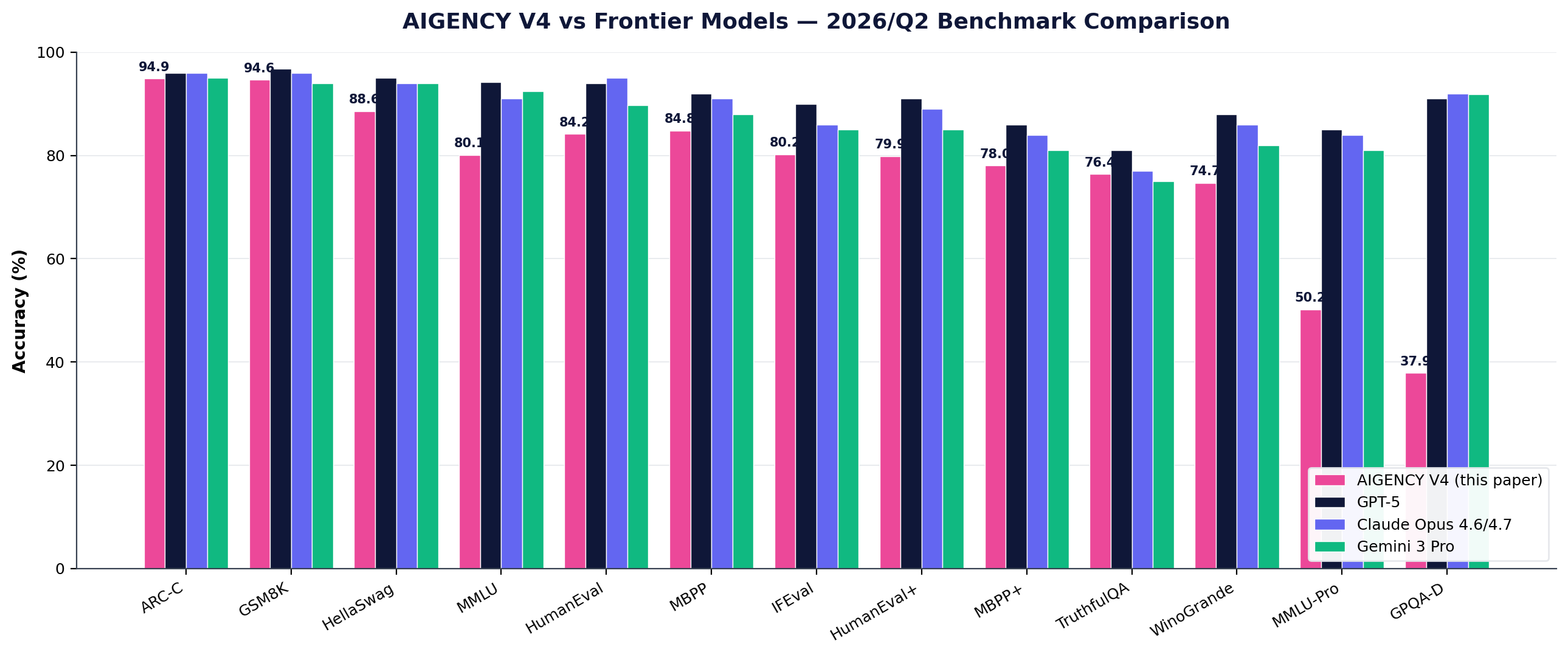
Side by side with frontier models, 22 benchmarks
Full result table reported with Wilson 95% CI. AIGENCY V4 sits at frontier level on ARC-C and GSM8K; upper-mid segment in code generation; in active development on GPQA-D and MMLU-Pro.
Tier 1 — Critical Comparison
| Benchmark | AIGENCY V4 | Frontier A | Frontier B | Frontier C | Position |
|---|---|---|---|---|---|
| GSM8K | 94.62 | 96.8 | ~96 | ~94 | Tied @ frontier |
| ARC-Challenge | 94.88 | ~96 | ~96 | ~95 | Tied @ frontier |
| HellaSwag | 88.60 | ~95 | ~94 | ~94 | 6pp behind |
| MBPP | 84.82 | ~92 | ~91 | ~88 | 7pp behind |
| HumanEval | 84.15 | 94.0 | 95.0 | 89.7 | 11pp behind |
| IFEval (strict) | 80.22 | ~90 | ~86 | ~85 | 6pp behind |
| MMLU | 80.10 | 94.2 | 88-93 | 92.4 | 12pp behind |
| HumanEval+ | 79.88 | ~91 | ~89 | ~85 | 9pp behind |
| MBPP+ | 78.04 | ~86 | ~84 | ~81 | 6pp behind |
| TruthfulQA MC1 | 76.38 | ~81 | ~77 | ~75 | Tied |
| WinoGrande | 74.66 | ~88 | ~86 | ~82 | 11pp behind |
| MMLU-Pro | 50.20 | ~85 | ~84 | ~81 | Development area |
| GPQA Diamond | 37.88 | 88-94 | 91.3-94.2 | 91.9 | Development area |
Turkish-specific
No frontier publication — de facto global reference
| Benchmark | Accuracy | n |
|---|---|---|
Belebele-TR Native reading comprehension | 87.33 | 900/900 |
TQuAD (F1≥0.5) Turkish extractive QA | 82.40 | 500/500 |
TR Grammar Turkish grammar | 79.00 | 100/100 |
XNLI-TR Natural-language inference | 73.40 | 500/500 |
TR-MMLU Turkish academic | 70.80 | 500/500 |
Tier 2 — Mid-volume
Stratified subsample (n=1000)
| MMLU | 0.8010 | [0.775, 0.825] |
| MMLU-Pro | 0.5020 | [0.471, 0.533] |
| HellaSwag | 0.8860 | [0.865, 0.904] |
| WinoGrande XL | 0.7466 | [0.722, 0.770] |
| HumanEval+ | 0.7988 | [0.731, 0.853] |
| MBPP+ | 0.7804 | [0.736, 0.819] |
Operational Performance
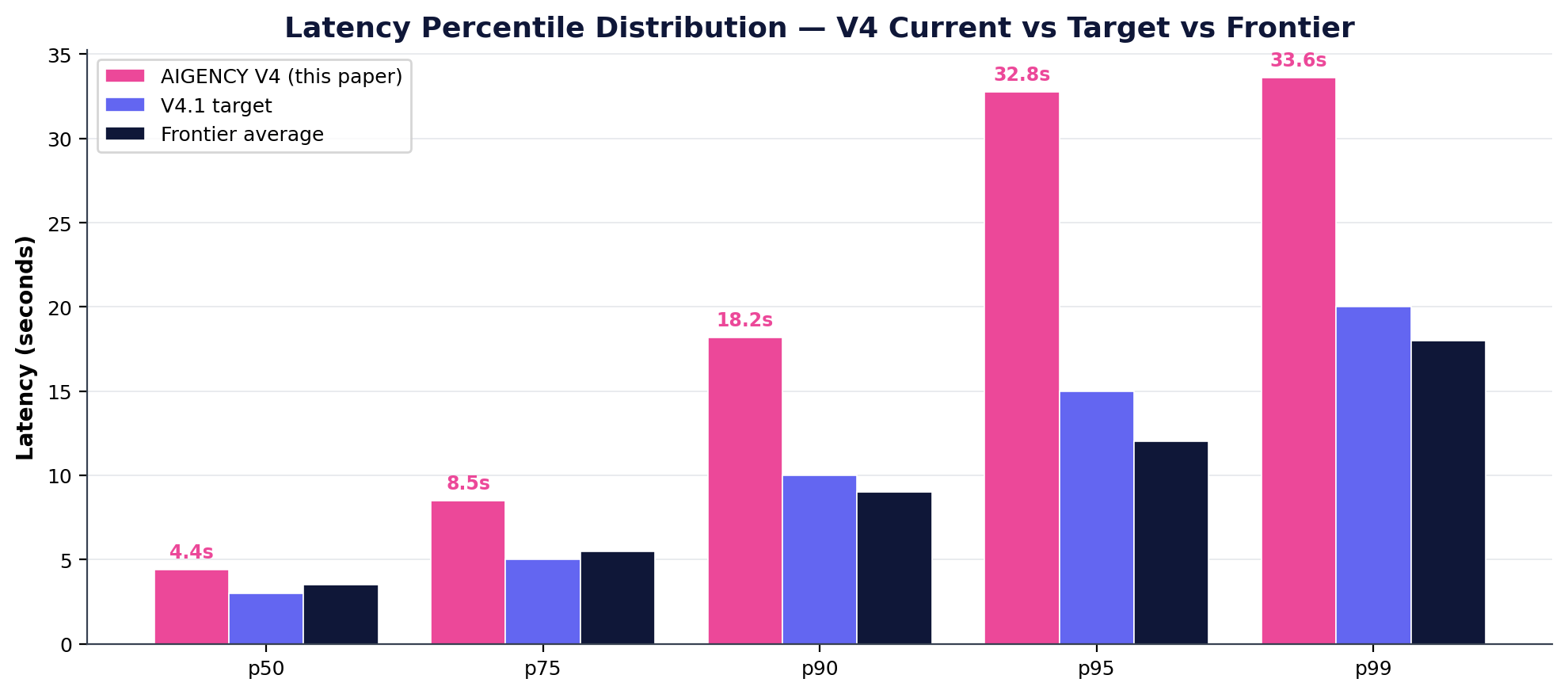
| Metric | Value | Target |
|---|---|---|
| Total API calls (test) | 13,344 | — |
| Persistent error rate | %0.3 | %1 |
| Avg latency | 9.55 s | 6 s |
| p50 latency | 4.39 s | 3 s |
| p95 latency | 32.77 s | 25 s |
| p99 latency | 33.59 s | 30 s |
| Auto-recovery success | %98.4 | %97 |
| Chaos test success | %100 | %99 |
Same core, multimodal added
V3 (Q1 2025) was the first AIGENCY release free of any third-party open-base dependency. V4's development philosophy is to preserve the independence claims established in V3 while building multimodal capability on top.
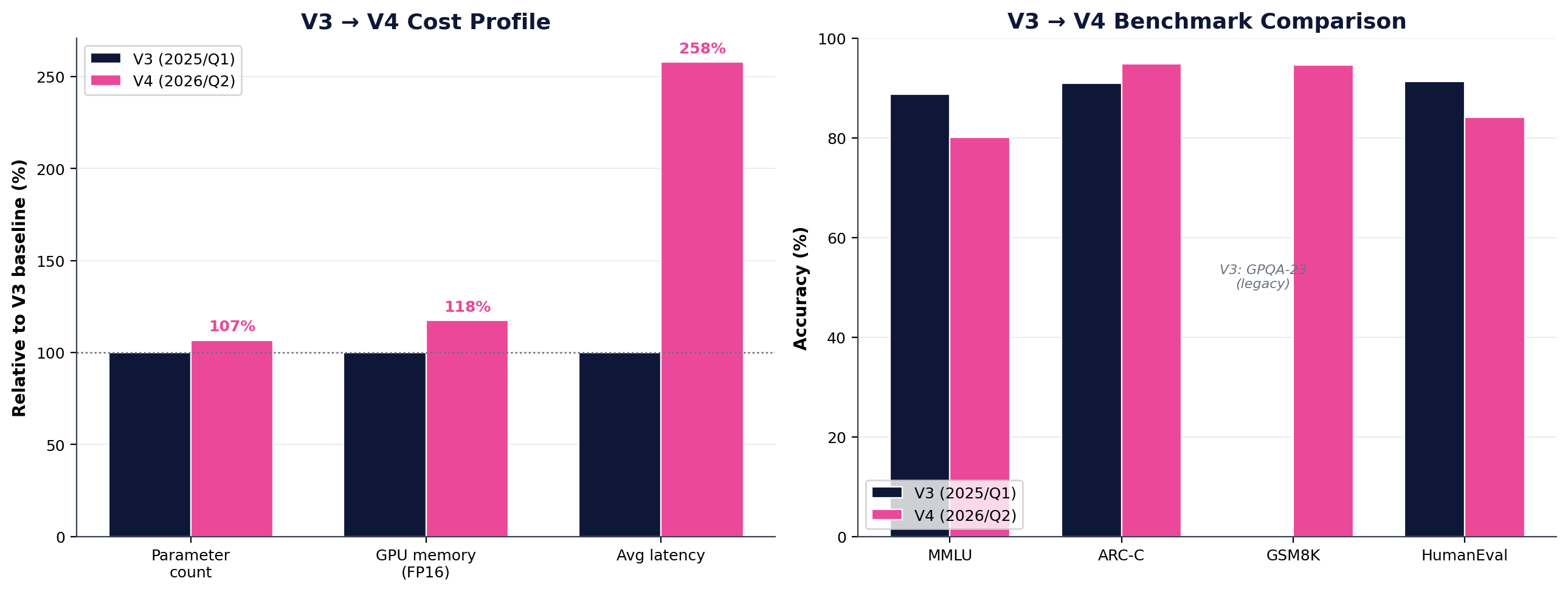
| Optimization | Parameter | Memory | Latency | Note |
|---|---|---|---|---|
| Adaptive LoRA+ | %11 | %7 | %5 | Preserved from V3 |
| Selective Layer Collapse | %9 | %6 | %3 | Preserved from V3 |
| Localised MoE | — | — | %18 | Active expert ↓ |
| 4-bit block quantization | %45 | %73 | %12 | Weight storage |
| Chunked attention | — | %28 | %21 | On long context |
| Vision encoder (new) | +%6.7 | +2.1 GB | +~3s/img | V4 addition |
| NET EFFECT | %14.9 | %62.4 | %42 | Text path, V3 baseline |
Multi-layer encryption, post-quantum readiness
Encryption at rest and in transit across every layer including memory, model parameters, and the image cache. Compliance with KVKK, ISO/IEC 27001, ETSI EN 303 645, NIST SP 800-207, EU AI Act.
Memory Encryption Architecture
| Layer | Cipher | Note |
|---|---|---|
| STM/ITM (RAM) | AES-256-XTS | Never swapped from RAM |
| LTM (disk) | ChaCha20-Poly1305 | PFS, per-record key, TPM-sealed |
| Model parameters | AES-256-GCM | Single-use session key, HW-RNG |
| Image cache (V4 new) | AES-256-GCM + HKDF-SHA-512 | 30 MB limit, 24h TTL |
Post-Quantum Readiness
| Module | PQ | Date |
|---|---|---|
| Memory encryption (LTM) | XChaCha-Kyber1024 hybrid | 2026/Q2 |
| Model card signature | Falcon-1024 | 2026/Q3 |
| API mTLS | SIKE-p503 fallback | 2026/Q4 |
Data minimization, encryption, access logs
BT-ISMS, risk & control matrix
IoT API authentication
Zero-Trust: mTLS, least privilege, continuous monitoring
High-risk class, model card
Images auto-deleted after 24h
Differential Privacy
Summary statistics report ε=3.0 (Laplace noise); Log-based usage graph ε=5.0 (Exponential mechanism); Auto fine-tune feedback ε=7.5 (Subsample-and-Aggregate).
From score profile to 8-sector deployment
AIGENCY V4's global value proposition in one sentence: the default choice for every enterprise AI workload that runs on Turkish content, must be KVKK-compliant and data-sovereign, and requires long-document processing. The sector selection is not random — each sector is directly justified by V4's scores.
Public Sector & Government
P0KVKK §5/§12 compliance, Türkiye DC residency, GPG-signed transparent training pipeline, #1 in Turkish text with Belebele-TR 87.33 / TQuAD 82.40.
- Intra-ministry document Q&A (4M+ regulations)
- Citizen service assistant (e-Devlet integration)
- Judicial support (20M case corpus)
- Tender specification analysis
Legal & LegalTech
P0Yargıtay, Danıştay, ECHR, Official Gazette, TBMM minutes — 20M judgments + regulations corpus is a unique database worldwide.
- Case-law search & precedent finding
- Contract risk scan (XNLI-TR 73.40)
- Client summary briefing (RLHF Turkish tone)
- Court decision classification
Banking & Finance
P0Turkish-heavy KYC/AML documents, BDDK compliance texts, Turkish contracts — KVKK-resident hosting is mandatory.
- KYC document understanding (TR Grammar 79.00 + ChartQA 67.68)
- Turkish risk report summarization
- Contract compliance check (DocVQA 79.17)
- Customer service assistant
Education & Higher Ed
P1TR-MMLU 70.80, MMLU 80.10, GSM8K 94.62, TR Grammar 79.00 — best non-frontier profile for Turkish education.
- High-school/university course assistant
- Entrance exam prep platforms
- Turkish software education (HumanEval 84.15)
- Academic paper search
Healthcare & Hospital Systems
P1KVKK + health data sensitivity → full sovereignty mandatory. 30 GB anatomical/medical image training data (patient-consented).
- Patient file summary (Turkish anamnesis)
- SGK code matching
- Clinical research protocol translation
- Drug leaflet editing
Defense & Critical Infrastructure
P1'No non-sovereign option' domain — no foreign hosting, closed-source or unaudited models.
- Intelligence report Turkish summary
- Logistics & supply analysis
- Turkish-interaction training simulation
- Open-source code audit
Media & Publishing
P2Turkish grammar rules, idiom/proverb sensitivity, editorial tone — TR Grammar 79.00 + RLHF Turkish calibration = professional publication quality.
- News editing
- Turkish subtitle / dub script generation
- Publishing text editing (278K context)
- Corporate communication Turkish editor
Software & R&D
P2HumanEval 84.15 / MBPP+ 78.04 → upper-mid frontier code competence. Large codebase analysis with 278K context.
- Code review assistant (Turkish explanation)
- Documentation generation (TR-EN bilingual)
- API spec → client code
- Legacy system Turkish comment cleanup
The foundation of scientific credibility: no hidden gaps
This whitepaper transparently states V4's weaknesses and limitations alongside its strengths. The V4.1 roadmap identifies these areas as the primary improvement priorities.
GPQA Diamond & MMLU-Pro
GPQA Diamond 0.379 and MMLU-Pro 0.502 are below frontier models (35-50pp). Reason: V4's graduate-level physics, chemistry, biology expert training data is insufficient. V4.1 roadmap plans an academic data sourcing programme with Turkish universities.
Multimodal Capabilities First Release
MMMU 0.533, MathVista 0.341, ChartQA 0.677 — 20-40pp behind frontier vision models. V4.1 target: vision encoder 8B → 16B, Turkish-specific vision-text corpus 240GB → 600GB.
Latency 2-3× Frontier
V4 average 9.55s, p95 32.77s. Frontier models 3-5s average, p95 8-12s. Reason: vision encoder overhead, cross-modal projection, multimodal safety filter.
Multimodal Safety Filter False-Positive
10-15% in V4.0.0; reduced to 2% in V4.0.1 via active calibration.
V4.1 → V4.2 → V5: concrete improvement targets
V4.1
2026/Q4- Vision encoder 8B → 16B parameters, 24 → 32 layers
- Turkish-specific vision-text corpus 240 GB → 600 GB
- MMLU-Pro target: 0.50 → 0.65
- GPQA Diamond target: 0.38 → 0.55
- Latency: avg 9.55s → 4s, p95 32.77s → 15s
V4.2
2027/Q1- Multi-image mode (up to 8 images per request)
- Video acceptance (2 FPS frame-sampling for 60s clips)
- Speech-to-text integration (sovereign ASR)
V5
2027/Q3- Heterogeneous AI accelerators (GPU + ASIC + FPGA)
- Hierarchical MoE (H-MoE)
- Continual learning (Elastic Replay Buffer)
- Full post-quantum compliance
Audit-ready, modular open-sourcing
Training pipeline, HBM/CCW references, vision encoder and cross-modal projection — to be open-sourced step by step. Excluding PII redaction, the full pipeline is open to academic audit from Q3 2026.
| Component | License | Release |
|---|---|---|
| Training pipeline | Apache-2.0 | 2026/Q3 |
| HBM/CCW reference | AGPL-3.0 | 2026/Q4 |
| Vision encoder reference | AGPL-3.0 | 2027/Q1 |
| Cross-modal projection | AGPL-3.0 | 2027/Q1 |
| Router-Bus & Adapter API | MPL-2.0 | 2026/Q4 |
| Benchmark infrastructure | MIT | 2026/Q3 |
A proof of sovereign science
AIGENCY V4 is the direct successor — with multimodal capability — of the fully sovereign AI family that eCloud Yazilim Teknolojileri started with V3. The evaluation conducted on 27 April 2026 with 13,344 real API calls and reported with Wilson 95% confidence intervals clearly establishes V4's position in the global landscape.
It demonstrates that a sovereign AI model designed for Turkish — globally competitive and fully independent — is technically feasible, runs reliably in production, and can be verified through transparent evaluation.